
티스토리 뷰
서울시 공유데이터 '따릉이' 수요 예측프로젝트
: 기상상황에 따른 따릉이 수요 분석 프로젝트
3일에 걸쳐 1차 미니프로젝트가 진행되었고 개인실습 + 조별실습이 진행되었다. 본가에 내려와있는 상황이라 비대면으로 참여했다.
데이터 전처리
데이터 셋
데이터셋은 온도, 강우여부, 오존 등 날짜별로 기상상황에 관련된 정보와 따릉이 대여수가 담겨있었다.
#데이터의 기본 정보 확인하기
data.info()
data.describe()
data.head()
data.tail()
data.info()를 통해 어떤 변수들이 있는지 확인하고 data.describe()를 통해 기초 통계량을 확인 할 수 있었다.
이후, 변수가 수치형인지 범주형인지 판단했다.
결측치 처리
#hour열의 결측치 확인
hour_missing_values = data['hour'].isnull().sum()
isnull().sum()을 통해서 결측치를 확인해보았다. 결측치를 처리하면 값을 0으로 반환한다.
우리조는 결측치 처리에 관해서 토론을 진행했는데, 조원 모두 다른 의견이라 신기했다.
나는 결측치가 많지 않다고 판단하여 dropna를 통해 없앴다. 분포를 확인하여 중앙값, 평균값, 최빈값, method = 'ffill' 등으로 처리하는 과정을 함께 살펴보았다.

kdeplot과 histplot을 통해 각 변수별로 분포를 확인하고 파악한 내용을 정리했다.
탐색적 데이터 분석
가설 검정 참고사항
- 유의수준 : 5%
- 숫자 → 숫자 상관분석
- 범주 → 범주 : 카이제곱 검정
- 범주 → 숫자 : t검정, 분산분석
- 숫자 → 범주 : 로지스틱 회귀모형을 통해 회귀계수의 p-value로 검정 수행
유의미한 관계인지 확인하기
범주형 변수

1시간 전 비가 오지 않은 경우 : 0
1시간 전 비가 온 경우 : 1
ttest_ind(count_no, count_yes)
x가 범주형 변수이므로 ttest를 통해 변수의 의미를 파악했다.
p-value가 0.05보다 작아 유의미하고 t통계량이 매우 낮아 강한 상관관계를 갖는 것으로 판단했다.
숫자형 변수
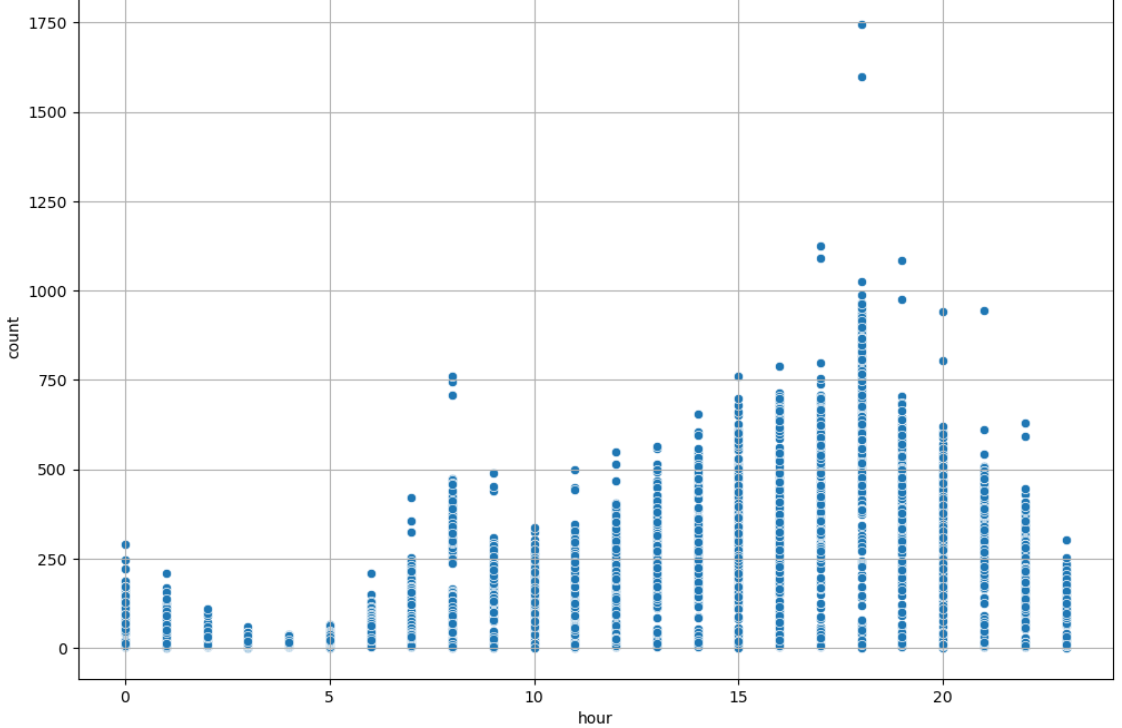
#시간대별 따릉이 대여량 분석
spst.pearsonr(df['hour'], df['count'])
p-value < 0.05이므로 유의미하고 상관계수 0.5 이상이므로 강한 상관관계를 확인했다.
데이터분석을 통해 각 변수별로 상관관계를 확인하여 가설검증을 진행했다.
여러가지 이유로 저번주 강의에 참석하지 못해서 걱정을 했는데 조원분들 덕에 1차미니프로젝트를 무사히 마칠 수 있었다.
'KT에이블스쿨' 카테고리의 다른 글
| [KT AIVLE] 웹 크롤링 (0) | 2024.04.15 |
|---|---|
| [KT AIVLE] 머신러닝 기초 이론 (2) | 2024.03.30 |
| [KT AIVLE] 데이터처리, 데이터의 분석 및 의미 찾기 (0) | 2024.03.25 |
| [KT AIVLE] Python 프로그래밍 & 라이브러리 (0) | 2024.03.25 |
| [KT AIVLE] KT에이블스쿨 5기 AI 개발자 트랙 합격 후기 (0) | 2024.03.25 |