KT에이블스쿨
[KT AIVLE] Python 프로그래밍 & 라이브러리
qkrgusqls
2024. 3. 25. 19:47
0222 - 0223은 기초 파이썬을 복습하는 시간을 가졌다.

CRISP-DM, Numpy, Pandas
기본 데이터 구조와 자료형
- 리스트는 저장소와 같은 역할을 한다.
- 딕셔너리의 특징과 활용
- 딕셔너리는 인덱스가 아니라 key로 조회한다.
- 여러형태의 자료형을 하나로 묶어준다.
데이터 분석 프로세스: CRISP-DM
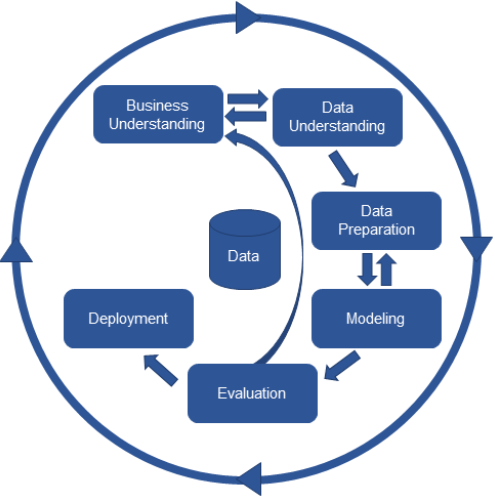
데이터 마이닝 프로세스를 위한 업계 표준 프로세스
CRISP-DM 개요 및 각 단계의 의미
- 비즈니스 이해 - 데이터 이해 - 데이터 준비 - 모델링 - 평가 - 배포
- 비지니스 문제 정의 : 무엇이 문제인가?
- 분석
- 데이터분석(EDA & CDA)
- 데이터 수집 및 웹크롤링
- 모델링
- 전처리
- 머신러닝
- 딥러닝
- 인공지능
- 시각지능
- 모델링을 위한 데이터 구조 만들기
- 모든 셀은 값이 있어야한다
- 모든 값은 숫자여야한다
- (필요시) 숫자의 범위가 일치해야한다
강사님께서 CRISP-DM 개념은 데이터 분석 관련 면접에서 강조하기 좋은 주제라고 하셨다.
Numpy와 Pandas
- Numpy: 수치 연산을 위한 라이브러리
- Pandas: 비지니스 데이터 표현과 관련된 기능
데이터 프레임 다루기
고유값을 확인하기 : unique()
행조건 확인하기 : iloc()
- 조건문 형태 → 조건문을 대괄호안에 넣으면 된다.
- 각 조건은 소괄호 안에 묶어야 한다.
열에서 지정된 값을 포함하는 값을 선택하기 : isin()
selected_cities = df[df['City'].isin(['New York', 'Los Angeles', 'Chicago'])]
'New York', 'Los Angeles', 'Chicago' 중 하나를 포함된 모든 행을 선택한다.
지정된 범위 내의 값을 선택하기 : between()
selected_rows = df[df['Age'].between(18, 30)]
'Age'가 18부터 30사이의 값을 가진 행을 선택한다.
그룹화하여 데이터를 분석하는 방법 : groupby()
grouped_df = df.groupby('Department')
average_salary = grouped_df['Salary'].mean()
부서별로 데이터를 그룹화하고 'Salary' 열의 평균을 계산하는 코드이다.
아직까진 파이썬 기초 문법 강의로 강사님께서 천천히 설명해주셨다. 복습하는 느낌으로 실습을 할 수 있어서 좋았다.
생각보다 모르는 메서드가 많아서 꼼꼼히 공부해보아야겠다.